Efficient GPU Path Rendering Using Scanline Rasterization
Rui Li, Qiming Hou, Kun Zhou
ACM Transactions on Graphics (SIGGRAPH Asia) 2016
Abstract
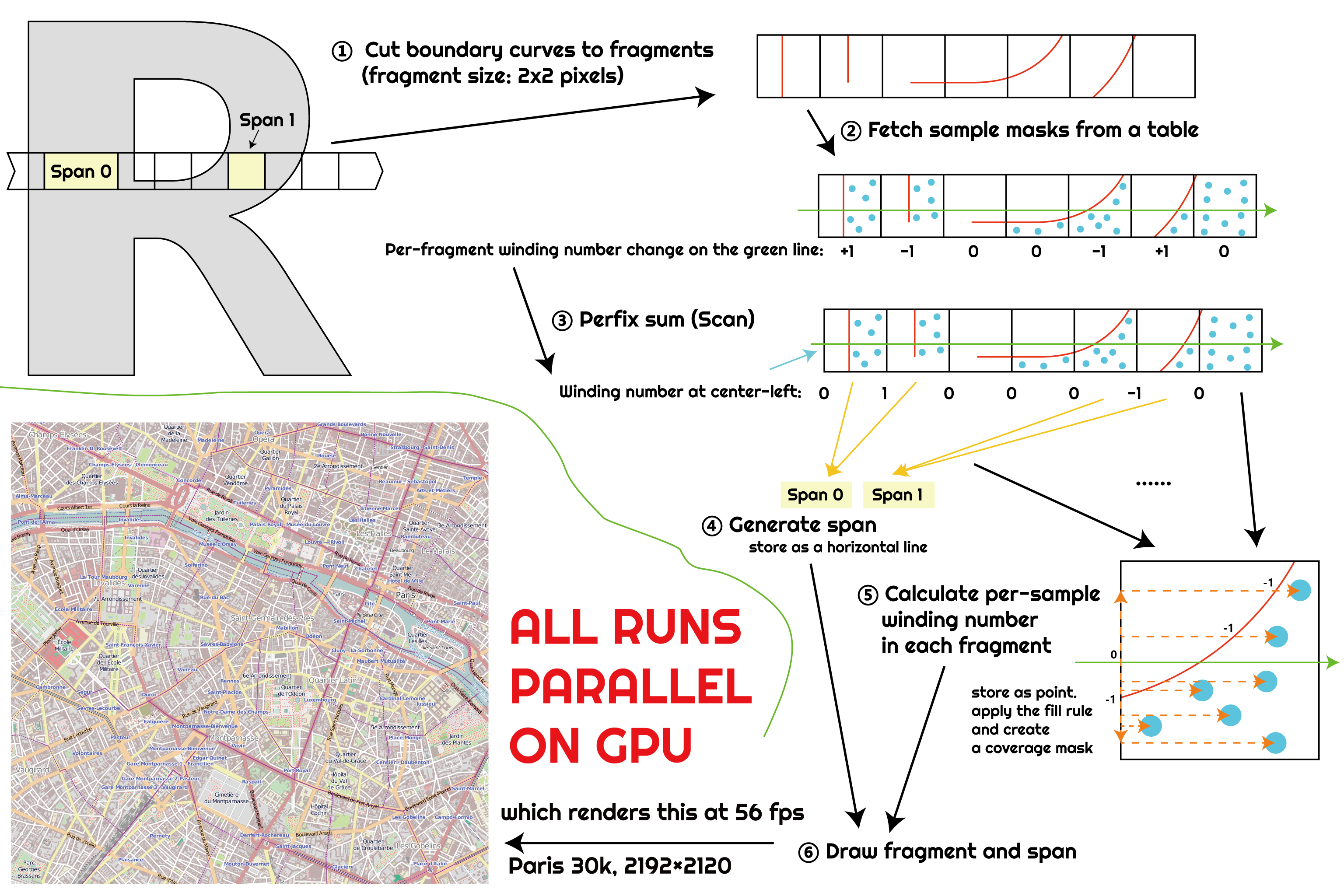
We introduce a novel GPU path rendering method based on scanline rasterization, which is highly work-efficient but traditionally considered as GPU hostile. Our method is parallelized over boundary fragments, i.e., pixels directly intersecting the path boundary. Non-boundary pixels are processed in bulk as horizontal spans like in CPU scanline rasterizers, which saves a significant amount of winding number computation workload. The distinction also allows the majority of our algorithm steps to focus on boundary fragments only, which leads to highly balanced workload among the GPU threads. In addition, we develop a ray shooting pattern that minimizes the global data dependency when computing winding numbers at anti-aliasing samples. This allows us to shift the majority of winding-number-related workload to the same kernel that consumes its result, which saves a significant amount of GPU memory bandwidth. Experiments show that our method gives a consistent 2.5× speedup over state-of-the-art alternatives for high-quality rendering at Ultra HD resolution, which can increase to more than 30× in extreme cases. We can also get a consistent 10× speedup on animated input.
BibTeX
@article {GPUpathtracingSA16,
title = {Efficient GPU Path Rendering Using Scanline Rasterization},
author = {Rui Li and Qiming Hou and Kun Zhou}
journal = {ACM Transactions on Graphics},
volume = {35},
number = {6},
pages = {},
year = {2016}
}